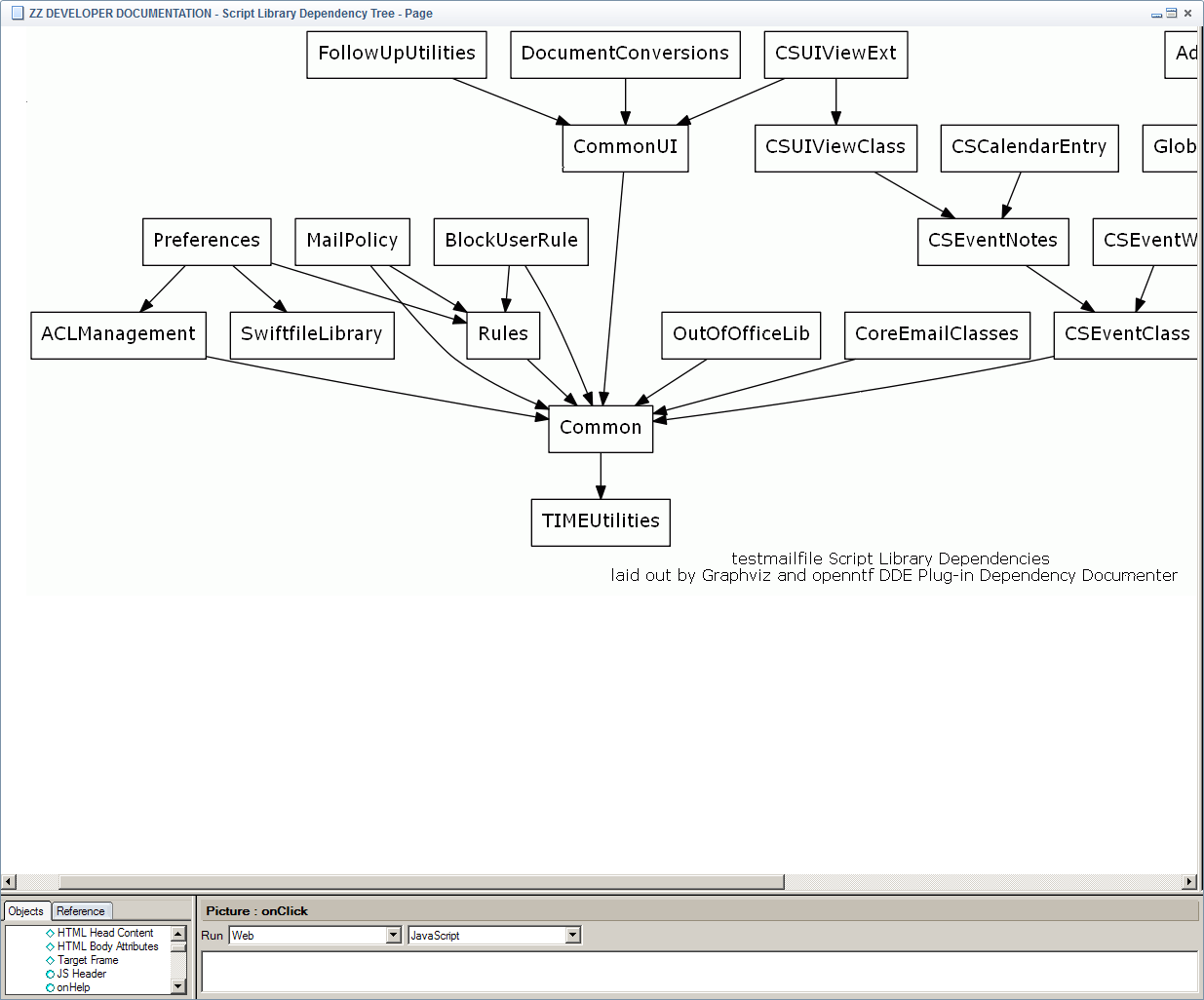
There are two syntaxes to call OLE objects, one is using := like this:
Set myRange = ActiveDocument.Content
myRange.Find.Execute FindText:="hi", ReplaceWith:="hello", Replace:=wdReplaceAll
Unfortunately LotusScript does not know how to deal with this, so you have to list the arguments exhaustively and in their correct order, including arguments which one does not really need.
Usually I can figure the syntax pretty quickly, but this one was really fiddly, so here is my function in all its glory.
I’ve tested it on Notes 9.0.1 and Word 2010, German version – YMMV.
[code language=”vb”]
‘/*************************************************************************************
‘ * Function FindAndReplaceWithinWordOLEObject:A function to find and replace some string within an inputted word document.
‘ * This function has been written because the OLE Call to the function is complicated and LotusScript does not
‘ * allow this syntax : .Execute FindText:="hi", ReplaceWith:="hello", Replace:=wdReplaceAll
‘ * @param varWordDocument a Word Document. (e.g. Application.ActiveDocument)
‘ * strFindThis the string I want to replace
‘ * strReplaceWithThis the replacement string
‘ * @return true if successful.
‘ * @author Andrew Magerman/Magerman/NotesNet
‘ * @version May 9, 2014
‘ *************************************************************************************/
Function FindAndReplaceWithinWordOLEObject(varWordDocument, strFindThis As String, strReplaceWithThis As String) As boolean
On Error GoTo ErrorHandling
Print "version 7"
‘documentation of these values at end of function
Dim FindText As Variant
Dim MatchCase As Variant
Dim MatchWholeWord As Variant
Dim MatchWildcards As Variant
Dim MatchSoundsLike As Variant
Dim MatchAllWordForms As Variant
Dim Forward As Variant
Dim Wrap As Variant
Dim SearchFormattting As Variant
Dim ReplaceWith As Variant
Dim ReplaceZeroOrOneOrAll As Variant
FindText = strFindThis
MatchCase = True
MatchWholeWord = False
MatchWildcards = False
MatchSoundsLike = False
MatchAllWordForms = False
Forward = True
‘The folowing are the valid constants for Wrap
‘Const wdFindStop = 0
‘Const wdFindAsk = 2
‘Const wdFindContinue = 1
Wrap = 1
SearchFormattting = True
ReplaceWith = strReplaceWithThis
‘The folowing are the valid constants for ReplaceZeroOrOneOrAll
‘Const wdReplaceAll = 2
‘Const wdReplaceNone = 0
‘Const wdReplaceOne = 1
ReplaceZeroOrOneOrAll = 2
FindAndReplaceWithinWordOLEObject = varWordDocument.Content.Find.Execute(FindText, MatchCase, MatchWholeWord, MatchWildcards, MatchSoundsLike, MatchAllWordForms, Forward, Wrap, SearchFormattting, ReplaceWith, ReplaceZeroOrOneOrAll)
Exit Function
Errorhandling:
Call LogError()
FindAndReplaceWithinWordOLEObject = false
Exit Function
%REM
expression .Execute(FindText, MatchCase, MatchWholeWord, MatchWildcards, MatchSoundsLike, MatchAllWordForms, Forward, Wrap, Format, ReplaceWith, Replace, MatchKashida, MatchDiacritics, MatchAlefHamza, MatchControl)
expression Required. A variable that represents a Find object.
Parameters
FindText
Optional
Variant
The Text To be searched for. Use an empty String ("") To search For formatting only. You can search For special characters by specifying appropriate character codes. For example, "^p" corresponds To a paragraph mark And "^t" corresponds To a Tab character.
MatchCase
Optional
Variant
True To specify that the find Text be Case sensitive. Corresponds To the Match Case check box In the Find And Replace dialog box (Edit menu).
MatchWholeWord
Optional
Variant
True To have the find operation locate only entire words, Not Text that Is part of a larger word. Corresponds To the Find whole words only check box In the Find And Replace dialog box.
MatchWildcards
Optional
Variant
True To have the find Text be a special search operator. Corresponds To the Use wildcards check box In the Find And Replace dialog box.
MatchSoundsLike
Optional
Variant
True To have the find operation locate words that sound similar To the find text. Corresponds To the Sounds Like check box In the Find And Replace dialog box.
MatchAllWordForms
Optional
Variant
True To have the find operation locate all forms of the find Text (For example, "sit" locates "sitting" And "sat"). Corresponds To the Find all word forms check box In the Find And Replace dialog box.
Forward
Optional
Variant
True To search forward (toward the End of the document).
Wrap
Optional
Variant
Controls what happens If the search begins at a point other than the beginning of the document And the End of the document Is reached (Or vice versa If Forward Is Set To False). This argument also controls what happens If there Is a selection Or range And the search Text Is Not found In the selection Or range. Can be one of the WdFindWrap constants.
Format
Optional
Variant
True To have the find operation locate formatting In addition To, Or instead of, the find text.
ReplaceWith
Optional
Variant
The replacement text. To Delete the Text specified by the Find argument, Use an empty String (""). You specify special characters And advanced search criteria just As you Do For the Find argument. To specify a graphic object Or other nontext item As the replacement, move the item To the Clipboard And specify "^c" For ReplaceWith.
Replace
Optional
Variant
Specifies how many replacements are To be made: one, all, Or none. Can be Any WdReplace constant.
MatchKashida
Optional
Variant
True If find operations match Text With matching kashidas In an Arabic-language document. This argument may Not be available To you, depending On the language support (U.S. English, For example) that you have selected Or installed.
MatchDiacritics
Optional
Variant
True If find operations match Text With matching diacritics In a right-to-left language document. This argument may Not be available To you, depending On the language support (U.S. English, For example) that you have selected Or installed.
MatchAlefHamza
Optional
Variant
True If find operations match Text With matching alef hamzas In an Arabic-language document. This argument may Not be available To you, depending On the language support (U.S. English, For example) that you have selected Or installed.
MatchControl
Optional
Variant
True If find operations match Text With matching bidirectional control characters In a right-to-left language document. This argument may Not be available To you, depending On the language support (U.S. English, For example) that you have selected Or installed.
MatchPrefix
Optional
Variant
True To match words beginning With the search string. Corresponds To the Match prefix check box In the Find And Replace dialog box.
MatchSuffix
Optional
Variant
True To match words ending With the search string. Corresponds To the Match suffix check box In the Find And Replace dialog box.
MatchPhrase
Optional
Variant
True ignores all white Space And control characters between words.
IgnoreSpace
Optional
Variant
True ignores all white Space between words. Corresponds To the Ignore white-space characters check box In the Find And Replace dialog box.
IgnorePunct
Optional
Variant
True ignores all punctuation characters between words. Corresponds To the Ignore punctuation check box In the Find And Replace dialog box.
Return Value
Boolean
%END REM
End Function
[/code]